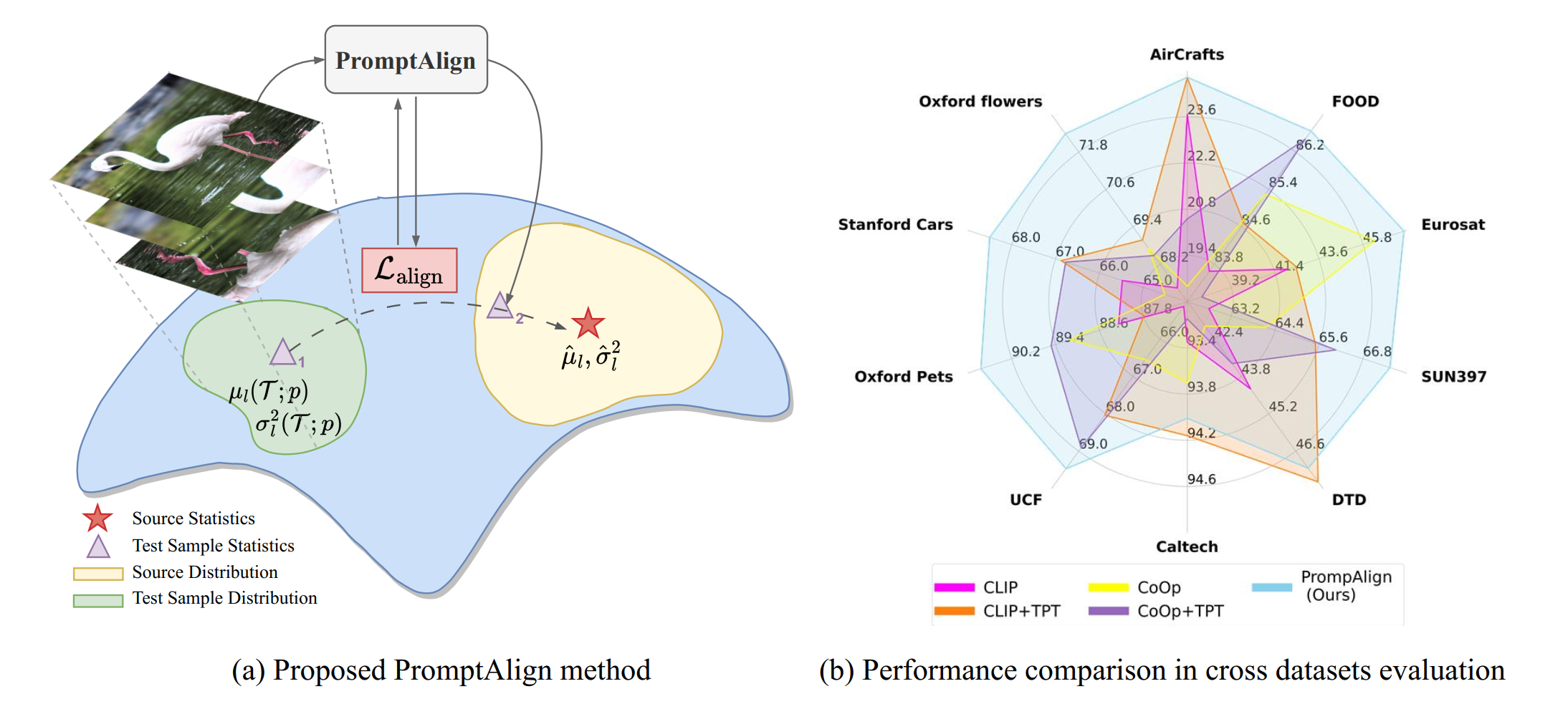
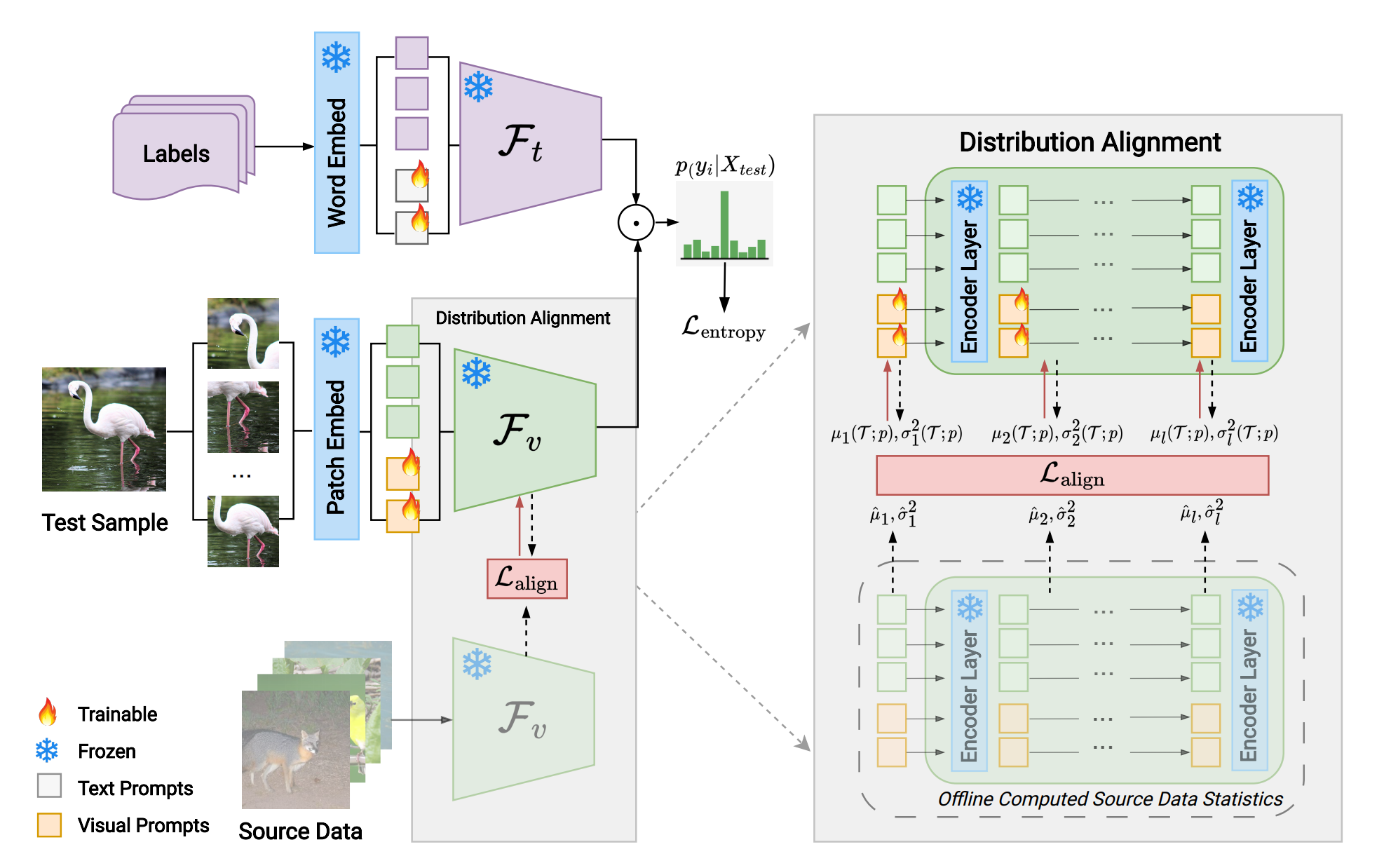
PromptAlign explicitly aligns the token disctribution statistics for each test sample with that of the source data
statistics. The source data statistics are computed using ImageNet as a proxy dataset, given by:
\begin{align}
{\hat{\mu}}_{l} = {\mu}_{l}(\mathcal{D}, {\theta}_v) \quad \text{and} \quad {\hat{\sigma}^2}_{l} = {\sigma}^2_{l}(\mathcal{D}, {\theta}_v) \quad
\label{eq:source-stats}
\end{align}
At test time, multiple augmented views of the sample are passed through the CLIP model and the token
distribution statistics -- mean and variance -- are computed as in Eq.\ref{eq:test-stats} and Eq.\ref{eq:test-stats2}, where
\(\bigg({{X~}^p}_{l, \mathrm{x}}\) is the prompt token embeddings at layer 𝑙.
\begin{align}
{\mu}_{l}(\mathcal{T} ; {p}) = \frac{1}{N_k} \sum_{\mathrm{x} \in \mathcal{H}(X)} {{X ~}^p}_{l, \mathrm{x}}
\label{eq:test-stats}
\end{align}
\begin{align}
{\sigma^2}_{l}(\mathcal{T} ; {p}) = \frac{1}{N_k} \sum_{\mathrm{x} \in \mathcal{H}(X)} \bigg({{X ~}^p}_{l, \mathrm{x}} - {\mu}_{l}(\mathcal{T} ; {p})\bigg)^2 ,
\label{eq:test-stats2}
\end{align}
The distribution alignment loss is computed between the offline computed source data statistics and the test sample
statistics across the transformer layers for all tokens as in Eq.\ref{eq:align-loss}. The resulting alignment loss from the
distribution shift is combined with the entropy loss to update the multi-modal prompts. For each sample, a single
update of the prompts are done, and it is reset to the original prompts for the next sample.
\begin{align}
\mathcal{L}_{\text{align}} = \frac{1}{L}\sum_{l=1}^{L} \bigg( \| {\mu}_{l}(\mathcal{T} ; {p}) - {\hat{\mu}}_{l} \|_1 + \| {\sigma^2}_{l}(\mathcal{T} ; {p}) - {\hat{\sigma}^2}_{l}\|_1 \bigg).
\label{eq:align-loss}
\end{align}